NVIDIAのTuringアーキテクチャがリアルタイムレイトレーシング出来るって主張する理由って何?
この記事は、徒然(ry
NVIDIAが2018年から、(主に)RTXシリーズの製品に組み込んでいるGPUのアーキテクチャであるところのTuringについて、特にレイトレーシングを絡めて、今更ではありますが、調べたことをまとめていきます。
要約
Turingアーキテクチャを使えば、リアルタイムなラスタライジングベースのレンダリングにレイトレーシングを取り入れられるかもしれない。その可能性がつかめるかどうかは、あなた次第。
Turingって何?
NVIDIAは、自社でデザインしたGPUのアーキテクチャに、数学者や物理学者の名前にちなんだ名前を付けており、Turing は、その中でも比較的新しいものです。
いままでのアーキテクチャとしては、Turingのひとつ前の世代のアーキテクチャであるPascalや、よりAIに特化したVoltaなどがあります。
このアーキテクチャの名前は、製品のブランド名であるGeForceや、開発プラットフォームの総称であるGTX、RTXともまた違う尺度でGPUの特徴を物語っています。ざっくり言えば、実際のチップ上の配置物や接続が異なっています。
このアーキテクチャ名の中でも、Turingへの進化は、「グラフィックスの再発明」と称されるほどの大きな飛躍をもたらしたとされています。
その要因の一つが、リアルタイムレイトレーシングの実現です。
Turingのいいところって何?
Turingは様々な方向に進化を遂げていますが、特にグラフィックスに関連が深いものは、
- シェーダーの実効速度の向上
- レイトレーシングを高速化するRTコアの導入
- Voltaで導入されたTensorコアを利用したAIによるグラフィックスの支援
- さまざまなモジュールを同時に稼働させるハイブリッドレンダリングアプローチの概念
あたりになってくると思います。
ここでは、これらの利点についてそれぞれ軽く解説し、それに続いて重要な単語についてを補足していく形で、Turingに関する記事タイトルの疑問を紐解いていきたいと思います。
シェーダーの実効速度の向上
シェーダーの実行効率の向上は、レンダリングの中で行う処理のほとんどの効率を引き上げるため、非常に重要です。
これには、新しいメモリ設計であるGDDR6の導入や、既存の共有メモリ・テクスチャキャッシング・メモリロードキャッシングが一つのユニットに統合されるなどの、メモリ的な要因があります。
しかし、ここでさらに重要なのは、浮動小数点演算のデータパスと同時に、整数演算のデータパスが利用できるという変更です。
スペックとしてよく記載されているCUDAコアは、GPU内で計算を行うモジュールの最小単位です。CPUのコアと同じように、それぞれに一つのスレッドが割り当てられて、同時に処理を行うことができます。
今までは、すべてのCUDAコアは同等に扱われていたのですが、Turingでは、整数演算担当のINT32コアと浮動小数点演算担当のFP32コアがあり、それぞれが独立したデータパスで駆動します。
これによって、浮動小数点演算の中に混じったデータのアドレス指定やフェッチのための整数演算の実行の際に、浮動小数点演算データパスが停止するということがなくなります。
NVIDIAが公表している以下の図の調査結果では、100個の浮動小数点演算命令ごとに、約36個の整数演算命令があるとされ、理想的には、この変更は36%の追加のスループットをもたらすとしています。
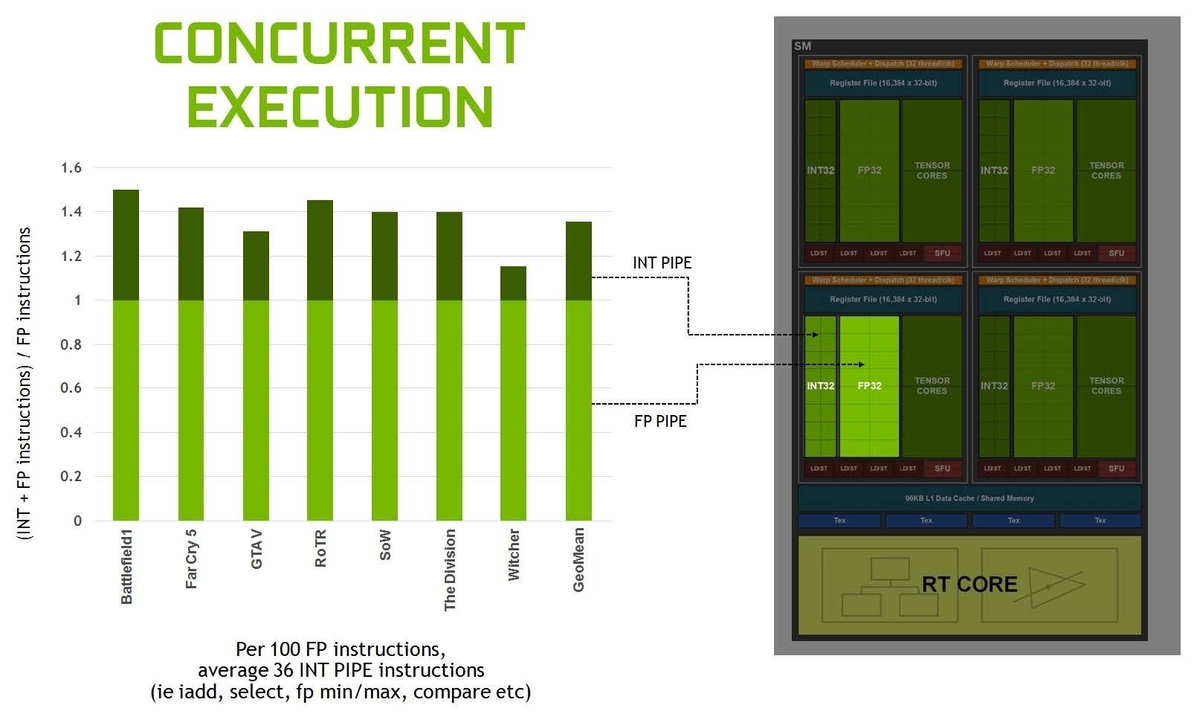 [1]
[1]
このシェーダーの処理効率の向上は、CUDAコアあたりのパフォーマンスを50%向上するとされており、Turingアーキテクチャの重要な進化の一つと言えます。
レイトレーシングを高速化するRTコアの導入
GPUは、レンダリングにおいて様々な処理を行いますが、Turingは、リアルタイムなレイトレーシングを実現するために、レイトレーシングに特化した処理を行う RTコア を導入しました。
RTコアは、レイトレーシングの主要な処理を、通常のCUDAコアを用いるよりも約10倍のパフォーマンスで実行します。
このRTコアは、Microsoft DirectX Raytracing(DXR)、Vulkan ray tracingなどのAPIから利用でき、レイトレーシングの処理を高速化します。
Voltaで導入されたTensorコアを利用したAIによるグラフィックスの支援
RTコアと同じように、AIもとい、ニューラルネットワークの処理に特化した Tensorコア を組み込むことで、グラフィックスにおいても様々な利点があります。
Tensorコアは、ニューラルネットワークの主要な処理を約8倍のパフォーマンスで実行します。
特に、レイトレーシングを組み込んだレンダリングでは、ノイズの除去など、ニューラルネットワークが得意とする課題が発生するため、これもリアルタイムレイトレーシングの実現に大きく寄与しています。
さまざまなモジュールを同時に稼働させるハイブリッドレンダリングアプローチの概念
この項目に関しては、アーキテクチャそのものの改善というよりも、アーキテクチャの進化がもたらした新たな選択肢と言った方が適切かもしれません。
今回、Turingを用いたリアルタイムレイトレーシングについて注目していますが、実際にはレンダリングのすべての工程をレイトレーシングで行うことは、Turingのスペックをもってしても不可能です。しかし、その中でレイトレーシングがもたらすリアリズムを、従来のレンダリングに取り入れることは不可能ではありません。
従来の方法でレンダリングを行いながら、追加でレイトレーシングを用いた結果を用いることで、レイトレーシングが特に得意とする、光の反射や屈折、影のシミュレーションの正確さを享受できます。
そして、上述した、RTコア、Tensorコア、そしてINT32コア及びFP32コアをすべて同時に用いることで、従来のレンダリングを行いながら、同時に補助的なレイトレーシングの処理、レイトレーシングによるノイズの除去を同時に行うことが可能となり、結果的に今までにないリアルな画像をレンダリングできます。
この手法をNVIDIAは ハイブリッドレンダリング と呼んでいます。
RTコアって何?
具体的に言うと、RTコアはレイトレーシングの処理の中で、レイとシーン内のポリゴンメッシュとの衝突判定を専門に行います。
Turingアーキテクチャを用いたレンダリングでは、シーン内の三角形を全てBVHという構造で管理しています。BVHについては、調べればたくさん情報が出てくると思いますので、ここでは割愛します。
このBVHで管理された三角形に対して、レイがどのように交差するかを判定するのがRTコアです。
RTコアによって実現されること
コストの高いレイの交差判定を専門とするRTコアの存在は、GPUを用いたレイトレーシングの処理を大きく単純化します。
従来のGPUを用いたBVHの交差テストでは、以下の図のように、シェーダーの実行時に何千もの命令を処理する必要がありました。
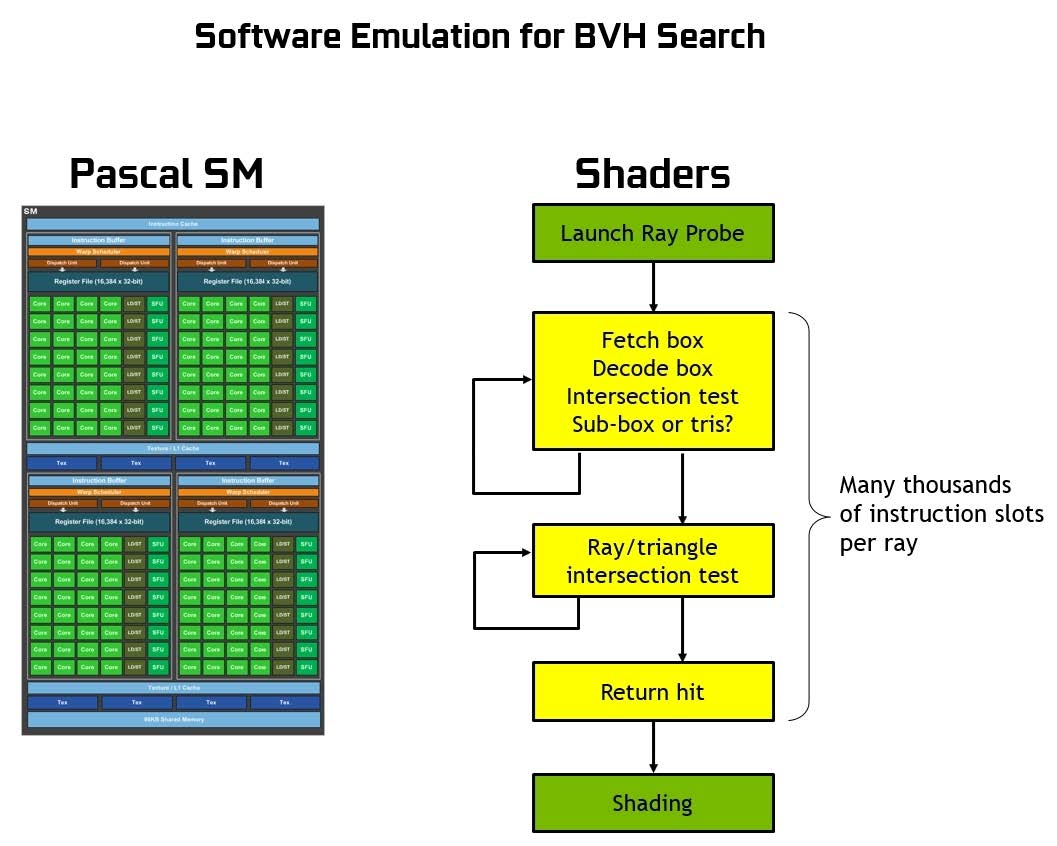 [1]
[1]
しかし、RTコアを用いる場合、ハードウェア上で決定された処理を行うため、シェーダーで多くの命令を処理する必要がありません。
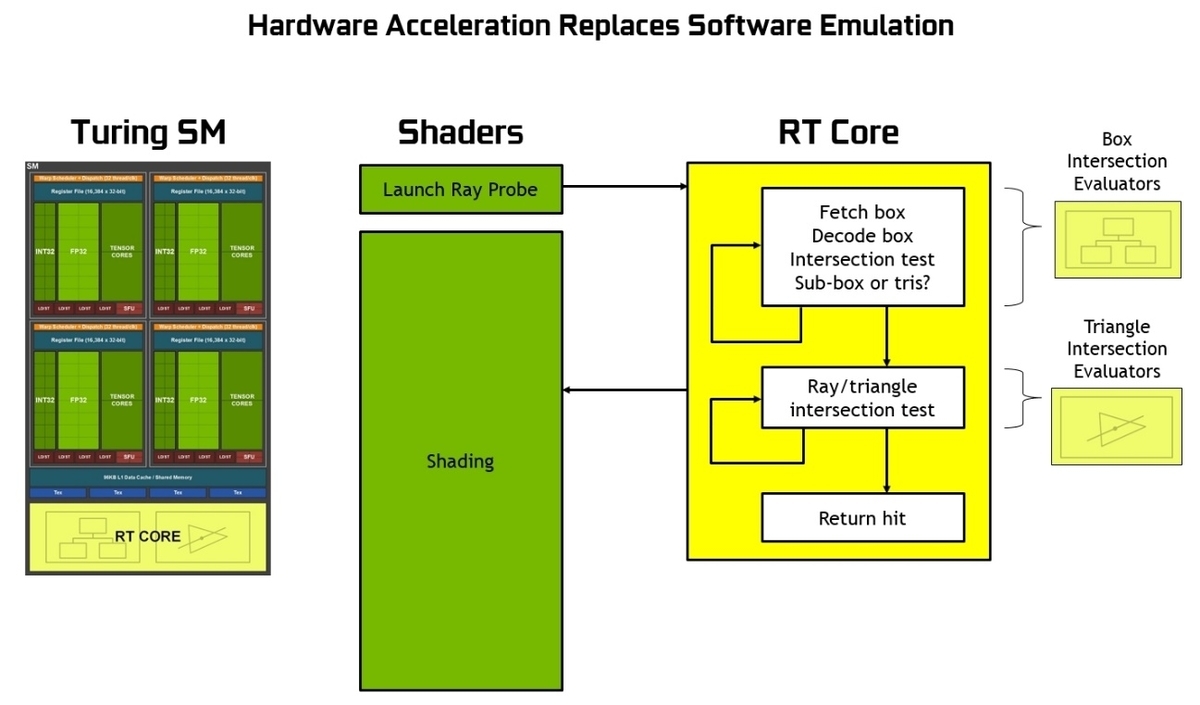 [1]
[1]
これによって、以下の図のように様々なオブジェクトに対してのレイの交差テストがPascalアーキテクチャの場合と比べて10倍近いパフォーマンスで実現できます。
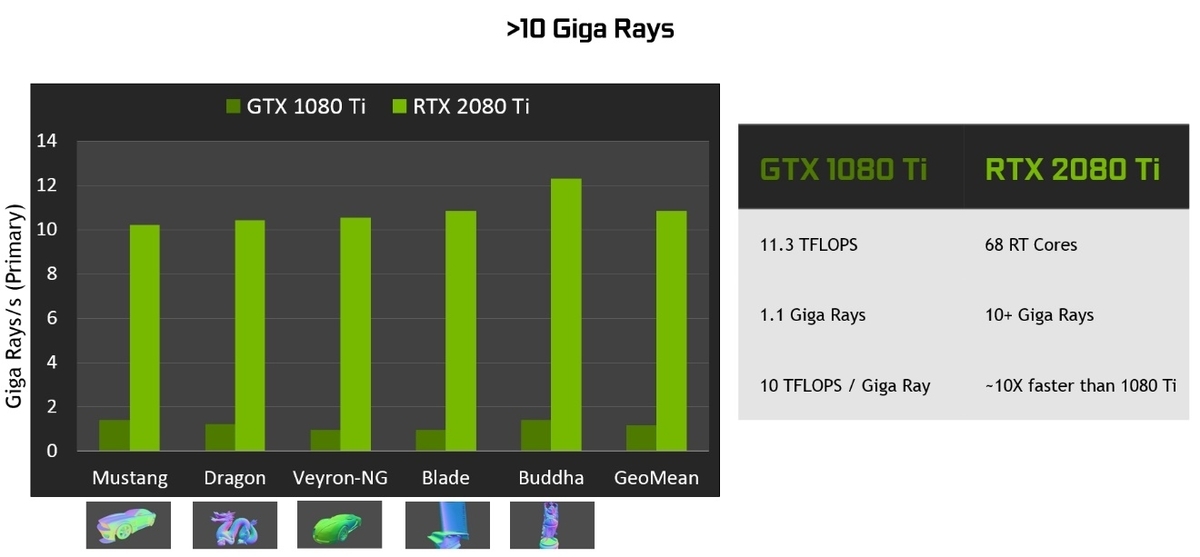 [1]
[1]
Tensorコアって何?
これまた具体的に言うと、Tensorコアはニューラルネットワークに必要不可欠な、行列演算を専門に行います。
そして、より高速なニューラルネットワークの演算が提供されると、様々な形でレンダリングに応用が出来ます。
グラフィックスに役立つ機能は、基本的にNVIDIA NGX(Neural Graphics Acceleration)と呼ばれるフレームワークを介してアクセスされます。
NGXは既にNVIDIAで訓練された、いくつかのニューラルネットワークおよびディープニューラルネットワークベースの機能をTensorコアを用いて動かせるようになっています。
Tensorコアによって実現されること
NGXには、リアルタイムレイトレーシングにも役立つ重要な機能が含まれます。
レイトレーシングは、反射や透過をシミュレーションすることで、今までにないリアルな表現を実現できる一方で、今までのラスタライズベースのレンダリングでは発生しなかったノイズが発生します。
これは、以下の画像のように、ピクセルごとの斑点のような形で現れます。
 [2]
[2]
このノイズは、レイトレーシングにおけるピクセルごとのレイの少なさによるものです。しかし、このノイズが起こらないほどのレイを生成するためのは、RTコアの高速さをもってしても不可能です。
このノイズの除去を、ニューラルネットワークを利用して高速に行う手法が ディープラーニングスーパーサンプリング(DLSS) です。
DLSSを用いることで、高品質な画像の生成のために必要なレイの数を大きく減らして、リアルタイムなレイトレーシングの実行をより現実的なものにします。
DLSSはNGXに含められているため、Tensorコアを使って高速に実行されます。
DLSSに関するより詳細な情報は、[3] などをご覧ください。
ハイブリッドレンダリングアプローチって何?
ここまで紹介したTuringの特徴や、Turingによって実現される技術を同時に利用することで、リアルタイムにレイトレーシングで生成された画像のような品質を得る唯一の方法がハイブリッドレンダリングです。
レイトレーシングの手法と比較して、既存のレンダリングの手法はラスタライズベースと呼ばれます。
ラスタライズベースのレンダリングは現実的なパフォーマンスで動作する一方で、光の反射や屈折、影に関しては、エラーが発生する可能性のある単純化をしなければ表現できないという制限があります。
一方で、レイトレーシングが光や影に関してリアルな表現を可能にするが、リアルタイムに全てをレイトレーシングでレンダリングするのは不可能です。
そこで、ハイブリッドレンダリングでは、既存のラスタライズベースの手法を行いながら、必要なところで部分的にレイトレーシングを適用します。そして、レイトレーシングの導入によって生まれるノイズを、DLSSを用いて低減します。
DirectXやVulkanなどのグラフィックスAPIも、同じように進化しており、既存のレンダリング手法とレイトレーシングの処理の両方をGPUを用いて行う方法が生まれてきました。その進化に、Turingが提供する機能を組み合わせることで、ハイブリッドレンダリングが実現されます。
以下の例は、NVIDIA Turingを用いた実験での実際のハイブリッドレンダリングの様子です。
 [4]
[4]
RTX-OPsって何?
RTX-OPsは、ハイブリッドレンダリングの最適さを比較するためにNVIDIAが用意した指標です。
NVIDIAは1フレームのレンダリングに必要な時間の中で、以下のような配分でそれぞれのレンダリングのプロセスが実行されるとしています。
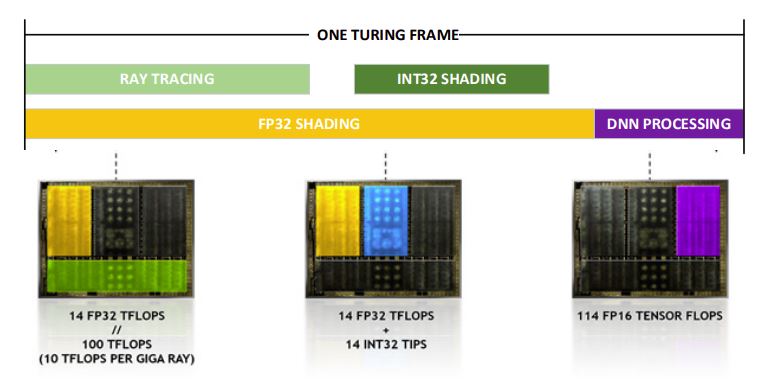 [1]
[1]
この場合のRTX-OPsを計算するのは簡単で、全体の時間に対してそれぞれの処理にかかった時間の割合とそれぞれの処理を行うモジュールの演算速度を掛けて、合計を求めるだけです。
ここでは、
- レイトレーシングが100TFLOPS相当で動作するRTコアで40%の時間で行われ、
- ラスタライズベースのレンダリングが14TFLOPSで動作するFP32コアで80%、14TIPSで動作するINT32コアで28%の時間で行われ、
- 最後のDLSSの処理が114TFLOPS相当で動作するTensorコアで20%の時間で行われる
とされているため、RTX-OPsは 78 = 14 * 80% + 14 * 28% + 100 * 40% + 114 * 20% となります。
このRTX-OPsの値は、GTX 1080Tiで11.3、RTX 2080 Tiで78となっているので、Turingは既存のアーキテクチャに対して約7倍の効率でハイブリッドレンダリングを実現していると言うこともできます。[1]
で、何?(結論)
Turingは、リアルタイムレイトレーシングの実現を目指した結果、ハイブリッドレンダリングに特化したアーキテクチャに落ち着いています。
ハイブリッドレンダリングの効率性を示すために、RTX-OPsという指標を作って比較していますが、その値はあくまで参考程度のものだと言えます。ライスタライズとレイトレーシングの役割を上手く分割しすることでいかにRTコアを最大限活用するのか、DLSSに代表されるNGXの機能や、ニューラルネットワークの利用でいかにTensorコアを最大限活用するのかによってRTX-OPsの値は大きく変化します。
結局のところ、Turingでも、いつも通りハードウェアの力を最大限利用できるアプリケーション作りが必須になりそうです。
参考文献
- [1] 『NVIDIA Turing Architecture Whitepaper』
https://www.nvidia.com/content/dam/en-zz/Solutions/design-visualization/technologies/turing-architecture/NVIDIA-Turing-Architecture-Whitepaper.pdf
- Turingアーキテクチャに関する情報と、画像はほとんどここから得ています
- [2] 『Interactive Reconstruction of Monte Carlo Image Sequences using a Recurrent Denoising Autoencoder』https://research.nvidia.com/publication/interactive-reconstruction-monte-carlo-image-sequences-using-recurrent-denoising
- [3] 『NVIDIA DLSS 2.0: AI レンダリングの大きな飛躍』https://www.nvidia.com/ja-jp/geforce/news/nvidia-dlss-2-0-a-big-leap-in-ai-rendering/
- [4] 『SIGGRAPH 2018 - PICA PICA and NVIDIA Turing』https://www.slideshare.net/DICEStudio/siggraph-2018-pica-pica-and-nvidia-turing
- 『NVIDIA テクノロジ』https://www.nvidia.com/ja-jp/technologies/
- 『Get Started With Real-Time Ray Tracing』https://developer.nvidia.com/rtx/raytracing#essentials
おまけ ~TensorCoreとRTCoreとTensorRT~
- TensorCore:Voltaで導入された行列計算用コア
- RTCore:Turingで導入されたBVHトラバーサル用コア
- TensorRT:DNNの推論高速化SDK
NVIDIAさん似た名前のもの多すぎじゃないですか...